---
title: "Did Authors Respond to Unjournal Evaluations?"
author: "The Unjournal"
date: last-modified
format:
html:
toc: true
toc-depth: 3
code-fold: true
code-summary: "Show code"
execute:
echo: true
warning: false
message: false
freeze: auto
---
::: {.content-visible when-format="pdf"}
The interactive tables in this appendix are available in the online version at <https://valentinklotzbuecher.github.io/llm-uj-research-eval/paper_response_analysis.html>.
:::
::: {.callout-note}
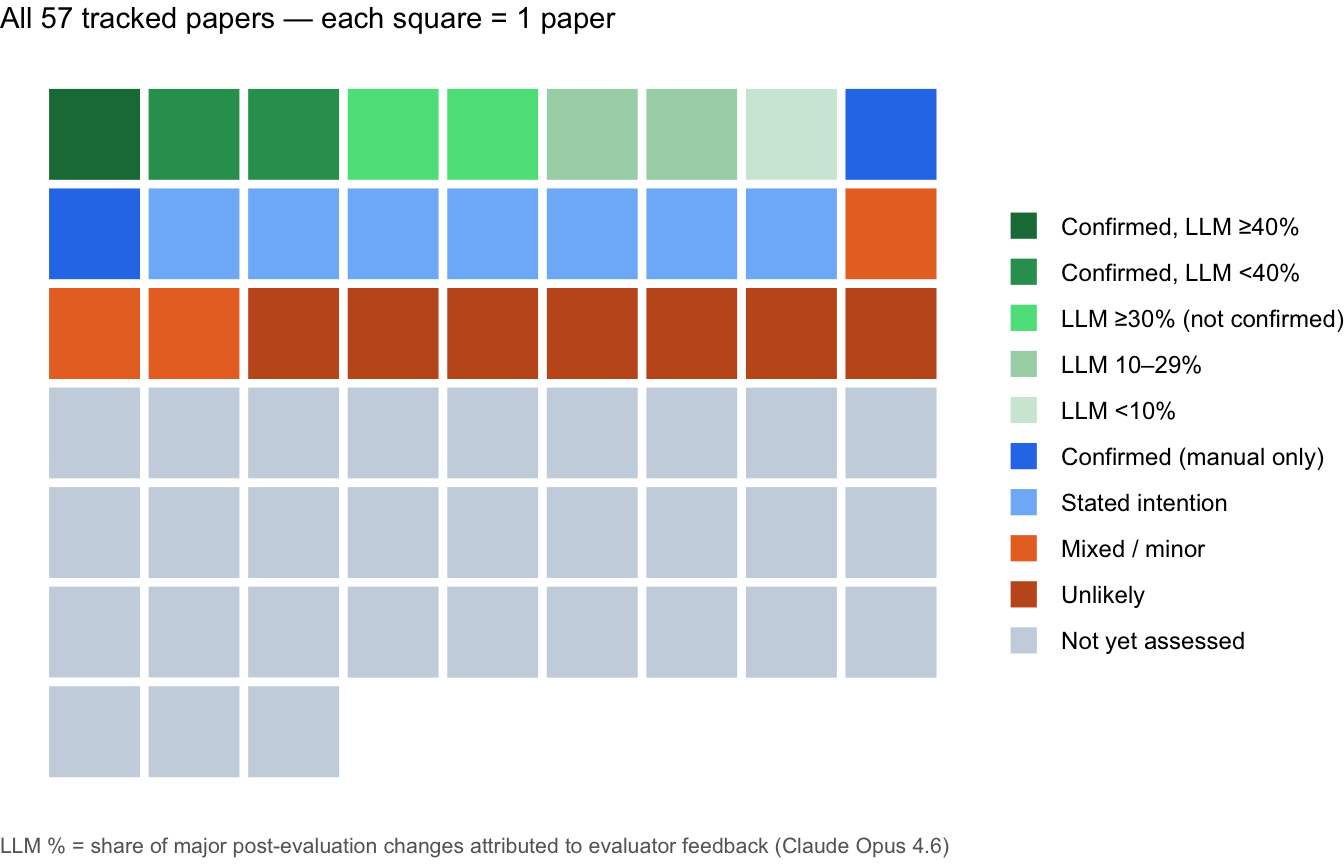
This page reports an April 2026 tracking snapshot covering 57 Unjournal evaluations. Adjustment status had been assessed for 22 of them, not the full set; completing and re-validating the remaining staff assessment is an ongoing goal. The page also includes an exploratory LLM comparison of eight paper pairs and the more careful July 2026 checks described below. See [Combined Evidence](#combined-evidence).
:::
::: {.callout-note}
## Comment or flag a correction
This page has Hypothes.is enabled. Select text and open the annotation sidebar from the upper-right edge of the page to leave an inline comment. We especially welcome corrections to document/version matching, missing public revisions, or our interpretation of whether a change reflects a suggestion. A free Hypothes.is account is required to post.
:::
## Overview
The Unjournal commissions open, structured evaluations of working papers in economics and social science. A natural question is whether this process changes research: do authors engage with feedback and revise their work?
This page draws on a tracking file covering 57 evaluations. In the April snapshot, 22 had an assessed adjustment status and 35 remained unassessed. For a subset, we also use automated PDF comparison and exploratory LLM screening. Background: [The Unjournal's knowledge base](https://globalimpact.gitbook.io/the-unjournal-project-and-communication-space/benefits-and-features/more-reliable-and-useful-evaluation/author-engagement-evidence).
```{r}
#| label: setup
#| code-summary: "Load data and define helpers"
library(dplyr)
library(ggplot2)
library(readr)
library(DT)
library(tidyr)
library(stringr)
library(glue)
library(jsonlite)
df <- read_csv("data/author_adjustment_manual.csv", show_col_types = FALSE)
reviewed_outcomes <- read_csv(
"data/paper_response_reviewed_outcomes.csv",
show_col_types = FALSE
)
stopifnot(
nrow(reviewed_outcomes) == 22,
sum(reviewed_outcomes$public_version_status == "no_observed_public_change") == 13,
sum(reviewed_outcomes$public_version_status == "later_public_version_reviewed") == 9
)
df <- df |>
rename(
paper_title = label_paper_title,
pubpub_link = dup_pubpub_final_links,
adj_status = `Adjusted_paper?`,
updated_manual = `Updated since UJ report -- manual confirmation`,
deposit_after = `deposit date > unjournal pub date`,
research_area = main_cause_cat_abbrev,
nb_link = notebookLM_link,
pub_status = publication_status,
wp_date = working_paper_release_date,
uj_pub_date = publication_date_unjournal
)
adj_labels <- c(
"Evidence of updating", "Stated intention to update",
"Mixed / minor updating", "Unlikely to update", "Not yet assessed"
)
df <- df |>
mutate(
adj_status_clean = case_when(
adj_status == "evidence of updating" ~ "Evidence of updating",
adj_status == "Stated intention to update" ~ "Stated intention to update",
adj_status == "mixed evidence/minor updating" ~ "Mixed / minor updating",
adj_status == "Unlikely to update" ~ "Unlikely to update",
TRUE ~ "Not yet assessed"
),
adj_status_clean = factor(adj_status_clean, levels = adj_labels),
author_response_clean = case_when(
author_response == "Formal response" ~ "Formal response",
author_response == "Informal" ~ "Informal response",
author_response == "None?" ~ "No response",
TRUE ~ "Not yet coded"
)
)
theme_uj <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(panel.grid.minor = element_blank(),
axis.text = element_text(size = base_size * 0.85),
plot.caption = element_text(size = base_size * 0.75, color = "grey50"),
legend.position = "right")
}
```
## Combined Evidence of Paper Updating {#combined-evidence}
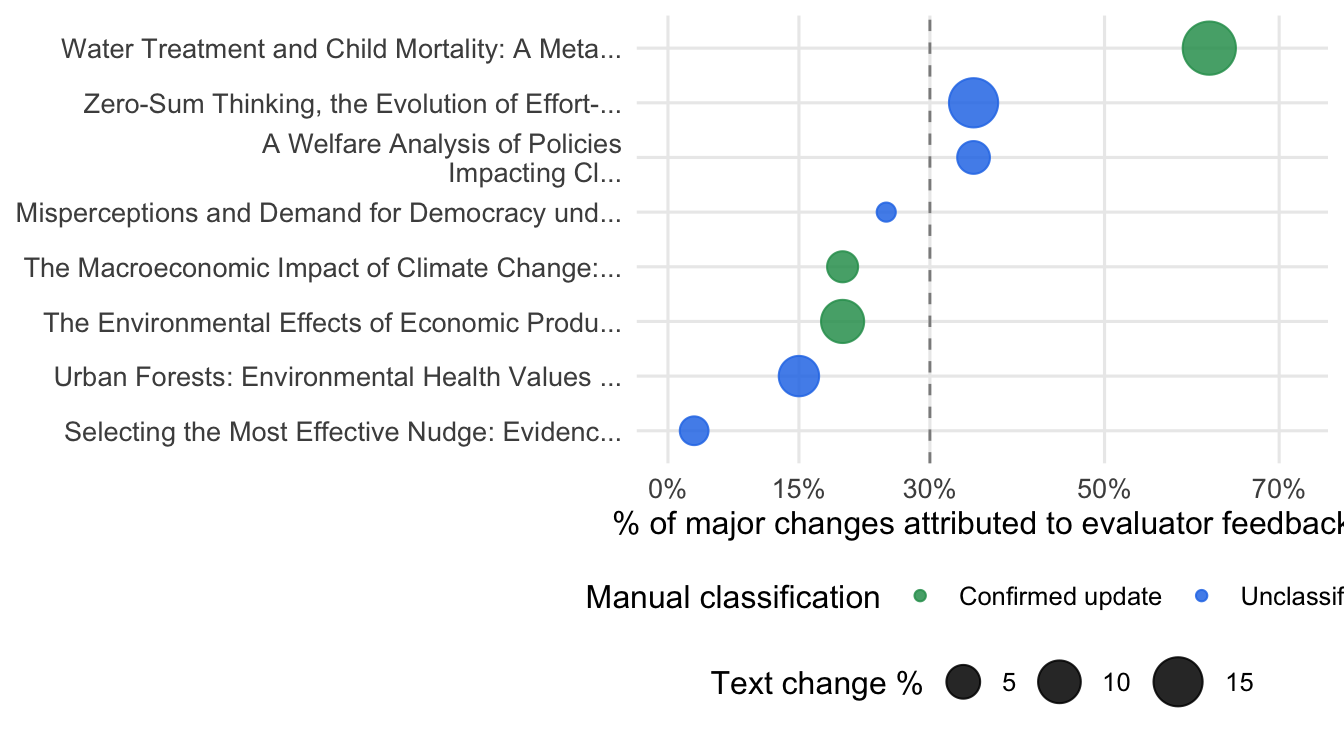
Two evidence streams are shown together: April tracking categories for 57 papers, of which 22 had an assessed adjustment status, and an exploratory Claude Opus 4.6 screen for eight papers where before/after PDFs were available and meaningful text changes were detected. The latter is a way to prioritize inspection, not a causal estimate.
::: {.callout-important}
## Current validation work (July 2026)
The April figures below remain the historical, partly assessed snapshot. A fresh July 18 source refresh captured 32 public current-paper versions and created 13 distinct before/after comparison records. Nine records passed document, identity, evaluation-mapping, and timing checks. Four superficially usable comparisons were excluded because the supposed later document predates the evaluation. We also audited all 17 cases where the initially selected input and current public PDF were byte-identical. Thirteen support a limited “no observed public document change” finding. Two apparent no-change cases were repaired by locating the correct later endpoint, one revised endpoint remains unavailable, and one record had no completed evaluation. These are coverage figures for a workflow, not findings that an evaluation caused a change.
For each candidate, the revised workflow preserves PDF snapshots and hashes, checks that the documents are the same paper and in the right order, records page- and section-level changes, and requires human review before any public claim of evaluation-linked updating. A newer PDF, a textual difference, or a model suggestion is not enough on its own.
:::
### Quick updated takeaways from the stricter screen
- **The substantive rates do not change.** The refresh found two additional different PDFs, but both predate their Unjournal evaluations. The reviewed evidence therefore remains 13 cases with no observed public document change and nine genuine later versions.
- **Whole-document controls matter.** A first card-level pass produced three medium-priority lexical matches. Checking the entire earlier paper downgraded all of them: the final deterministic pass found 17 low-priority review leads and no medium- or high-priority link. This does not overturn the manually reviewed correspondences below; it shows that simple lexical matching should not be used to create them.
- **The most informative low-priority leads illustrate different outcomes.** The macro-climate revision adds an appendix explicitly titled “Additional Robustness Checks,” consistent with a broad request for more checks but without identifying the evaluation as its source. The resilient-education revision adds questionnaire and protocol material about speakerphone use and other children, which documents the possible spillover issue but does not establish that only one student benefited. An apparent Urban Forests match disappears because alternative upwind-cone checks were already in the earlier appendix.
- **Coverage remains the binding constraint.** Among the 57 tracked records, 21 still need timeline validation and 15 current endpoints failed even after headless-browser fallback. Those cases cannot be treated as either updated or unchanged.
The automated screen is deliberately conservative. It requires an eligible version timeline, exact evaluation-document mapping, an evaluator quote with a valid line anchor, language that is new relative to the aligned change card, a whole-earlier-document preexistence check, and a cross-paper placebo benchmark. Passing produces a review lead only; it never assigns influence or enters the response-rate numerator automatically.
### Expanded case review (updated July 18, 2026) {#preliminary-case-review-july-16-2026}
For each of the initial seven cases, separate passes extracted exact suggestions, classified paper changes without seeing the evaluations, tried to disprove suggested links, and adjudicated the surviving candidates. We then manually checked the strongest apparent matches. Across these cases, the process examined 90 mechanically valid suggestion items and 99 changes classified as substantive. For *Urban Forests*, the bounded classifier reviewed 31 of 68 deterministic change cards; 16 of those 31 were substantive. Two additional cases were reviewed after correcting stale endpoint selections.
::: {.evidence-comparison-table}
| Paper | Evidence items | Change cards | Current assessment |
|---|---:|---:|---|
| *The Environmental Effects of Economic Production* | 4 | 28 | **One plausible aligned revision, attribution unconfirmed.** A new taxa-heterogeneity figure includes birds and partly matches a suggestion to assess productivity effects for bird taxa. The new analysis concerns agricultural income and eight taxa, and there is no author statement connecting it to the evaluation. |
| *Building Resilient Education Systems* | 10 | 10 | **Possible partial correspondence, attribution unconfirmed.** A request for stronger robustness checks overlaps with newly reported multiple-testing-adjusted results. Newly appended questionnaire and protocol material also documents speakerphone use and educational activity with other children, but it does not show that only one student benefited per call or rule out spillovers. These are standard design/reporting steps, and no response letter links them to the evaluation. |
| *The Macroeconomic Impact of Climate Change* | 6 | 7 | **Circumstantial correspondence only.** The revision adds an “Additional Robustness Checks” appendix and a new cross-sample robustness statement, both topically consistent with the evaluator's small-sample concern. The request was broad, related robustness material already existed, and no revision note identifies the source. |
| *A Welfare Analysis of Policies Impacting Climate Change* | 25 | 6 | **No supported link at present.** One automated candidate appeared to connect a request to clarify “international policies” with international examples. Manual checking found that those examples were already present in the earlier version, so we rejected the match. |
| *Zero-Sum Thinking, the Evolution of Effort-Suppressing Beliefs, and Economic Development* | 8 | 21 | **No positive link found.** Three possible pairings reflected timing only; five suggestions remained unmatched. |
| *Water Treatment and Child Mortality* | 14 | 11 | **One plausible aligned revision, attribution unconfirmed.** A new formal cost-effectiveness model, including cost per DALY and net DALYs averted, closely matches requests to deepen the cost analysis. No author response or revision memo links the addition to the evaluation. |
| *Urban Forests: Environmental Health Value and Disparities* | 23 | 16 | **Possible topical correspondences, attribution unconfirmed.** New wind-direction checks overlap with a confounding concern, and an NDVI footnote partly overlaps with a request about alternative vegetation measures. The strongest automated site-selection match was excluded because its source quote failed validation. A newer lexical match about alternative upwind measures was also downgraded after the whole-document check found alternative upwind-cone tests in the earlier appendix. |
| *Artificial Intelligence and Economic Growth* | 8 | 1 | **Direct documented evaluation-linked correction.** The public author response says the evaluation caught a significant proof error. The maintained document marks the exact invalid derivation and points to the corrected proof. The whole-document format change produced only one coarse change card, so this conclusion rests on the explicit response and document annotation rather than model matching. |
| *Adaptability and the Pivot Penalty in Science* | 8 | 1 | **No supported substantive implementation; one weak framing overlap.** A manual, section-aligned review found real revisions, but seven of eight suggestions were not implemented. A new caveat that the measured outcomes do not exhaust research quality weakly acknowledges the concern about omitted benefits without adding a benefit outcome. Several apparently responsive items were already in the evaluated version. |
:::
The nine reviewed comparisons now include one direct documented correction, two reasonably specific content alignments with attribution unconfirmed, three weaker correspondences, and three cases with no supported substantive match. Only the proof correction has explicit public evidence connecting the evaluation to the change.
### Overall and conditional response rates
The 22 reviewed endpoints support a more useful distinction than “changed” versus “unchanged.” The five outcome categories below are mutually exclusive.
::: {.outcome-summary-table}
| Reviewed endpoint outcome | Cases | Share of 22 |
|---|---:|---:|
| No observed public document change | 13 | 59% |
| Later version, but no supported substantive implementation | 3 | 14% |
| Later version with weaker correspondence | 3 | 14% |
| Later version with a reasonably specific alignment; attribution unconfirmed | 2 | 9% |
| Explicit public author link between evaluation and correction | 1 | 5% |
:::
Percentages are rounded; the counts are primary.
Overall, six of 22 reviewed endpoints (27%) show at least some correspondence between an evaluation point and a later change. Three of 22 (14%) show either a specific alignment or an explicit link, and one of 22 (5%) has an explicit public author statement connecting the evaluation to the correction.
Conditional on the nine papers with a genuine later public version, six (67%) show at least some correspondence, three (33%) show a specific or explicit alignment, and one (11%) has an explicit author link. Three of nine (33%) have no supported substantive implementation in the versions we reviewed.
These are descriptive rates for a small, selected, source-available set, not estimates for all 57 tracked evaluations. “Later version, but no supported implementation” is also not equivalent to “the authors ignored the suggestions.” Authors may have considered and rejected a suggestion, responded privately, revised a document we have not found, or changed the paper for unrelated reasons.
The identity checks now follow normalized DOIs where available and permit explicit, manually reviewed title aliases. They do not depend on exact title equality or infer aliases from a similar title. The evidence record stores the canonical title, any reviewed aliases, and which title matched the PDF; this matters for small changes such as “vs.” to “versus” and for future substantive retitling.
### Exploratory differences across research areas
The table counts only the 22 reviewed endpoints. “Any correspondence” includes weak correspondences and therefore should not be read as demonstrated influence.
::: {.field-pattern-table}
| Tracked research area | Reviewed endpoints | Later public version | Any correspondence overall | Any correspondence, conditional on update |
|---|---:|---:|---:|---:|
| Environment | 3 | 3 | 2/3 | 2/3 |
| Dev. economics / governance (LMICs) | 6 | 3 | 2/6 | 2/3 |
| Social impact of technology / AI | 2 | 1 | 1/2 | 1/1 |
| Innovation and meta-science | 4 | 1 | 0/4 | 0/1 |
| Global health (LMICs) | 6 | 1 | 1/6 | 1/1 |
| Economics, welfare, miscellaneous | 1 | 0 | 0/1 | — |
:::
Environment papers were more likely to have a later public version in this reviewed set, while global-health papers were less likely. Conditional response patterns cannot be ranked credibly: most area-specific denominators are one or three updated papers, and case selection partly reflects whether usable public versions could be recovered. The table is best treated as a prompt for stratified sampling as coverage expands.
### What kinds of evaluation points aligned with changes?
For an initial qualitative comparison, we assigned one primary evaluation aspect to each of the nine updated cases. This simplifies evaluations that often raised several distinct issues.
::: {.aspect-pattern-table}
| Primary evaluation aspect | Cases | Strongest observed result | Pattern in this review |
|---|---:|---|---|
| Correctable proof error | 1 | Explicit documented link | The clearest result was precise, checkable, and acknowledged publicly. |
| Specified additional analysis | 2 | Specific alignment, attribution unconfirmed | Both later papers added a closely related analysis, but neither linked it publicly to the evaluation. |
| Robustness, confounding, or measurement check | 3 | Weaker correspondence | Later checks overlapped with the concern, but standard-practice explanations remained plausible. |
| Broad theory, mechanisms, welfare, framing, or interpretation | 3 | No supported substantive implementation | The later versions changed, but the broad requested extensions were not clearly carried out. |
:::
The tentative pattern is that concrete, falsifiable requests are easier both to act on and to verify. This does not show that they cause more responsiveness: specificity is confounded with feasibility, observability, and the cost of the requested work. A credible next analysis should code all validated suggestions into a common taxonomy, double-code a sample, and compare response rates within updated papers.
### Pilot check for later related work
We also ran a targeted search for later work extending three updated papers where the reviewed version showed no supported substantive implementation. This is a separate outcome from revision of the evaluated paper.
::: {.later-work-table}
| Evaluated case | Public continuation checked | Pilot result |
|---|---|---|
| *A Welfare Analysis of Policies Impacting Climate Change* | The [July 2026 AER version of record](https://www.aeaweb.org/articles?id=10.1257%2Faer.20250166) and the October 2025 NBER full text | The AER item is the same paper, not a separate extension. Its full text was not publicly accessible in our check, so the content assessment still rests on the public NBER revision. We did not identify a separate later extension by the author team. |
| *The Pivot Penalty in Research* | The [May 2025 Nature paper](https://www.nature.com/articles/s41586-025-09048-1), supplement, and related records | This is the final version of the evaluated research line, not later separate work. It was accepted before the public Unjournal evaluation, and we did not identify a subsequent author-team extension addressing the unmatched suggestions. |
| *Zero-Sum Environments, the Evolution of Effort-Suppressing Beliefs, and Economic Development* | The [August 2025 NBER revision](https://www.nber.org/papers/w31663) and targeted title/author searches | The NBER revision is the same paper and is already included in the comparison above. We did not identify clearly attributable later work by the overlapping author team that implements the unmatched suggestions. |
:::
This pilot is deliberately phrased as “not identified,” not “does not exist.” Related-work tracking is harder than version tracking: titles, author teams, and empirical settings can all change. A scalable extension should record search dates and queries, require meaningful author overlap and a documented intellectual link, and keep “same paper,” “later extension,” and “unrelated related literature” as separate categories.
#### Detailed aligned review: *The Pivot Penalty in Research*
The initial comparison was too coarse because the later paper reorganized the manuscript and supplement. We therefore split the evaluated August 2024 bundle at the actual main-text/supplement boundary, aligned later sections by content rather than section number, and checked each validated suggestion against the February 2025 manuscript and the Nature main text and supplement. We also checked the Nature reporting summary, peer-review file, and source-data package for provenance and context; these are not treated as an Unjournal author response.
::: {.suggestion-review-table}
| Evaluation suggestion | What the later documents show | Verdict |
|---|---|---|
| Examine promotion or funding outcomes | The evaluated version already checked whether papers acknowledged funding. Later versions do not study promotion or funding received as an outcome. | Not addressed |
| Account for potential benefits omitted by the outcome measures | Later discussion newly notes that citation, publication, novelty, conventionality, and applied-value measures do not exhaust a multidimensional concept of research quality. It adds no benefit outcome. | Weak framing acknowledgment only |
| Examine decision-making behind pivoting | The evaluated version already discussed researchers weighing pivots and making sequential choices. Later versions add no choice model or new evidence on the decision process. | Not newly addressed |
| Analyze welfare or possible misallocation | Portfolio and pre-positioning policy discussion was already present. No welfare or misallocation analysis was added. | Not addressed |
| Test longer horizons, including the COVID/mRNA setting | Alternative citation windows and time-trend figures were already present. No new COVID/mRNA long-horizon test was added. | Not addressed as requested |
| Test when in a career or sequence researchers should pivot | Existing career-stage and sequential-dynamics material does not provide the requested timing-heterogeneity test. | Not addressed |
| Adjust for evolving journal preferences | We found no aggregate journal-preference adjustment in the later documents. | Not addressed |
| Define paper pivots by fields rather than journals | The evaluated supplement already reconstructed the paper-pivot measure using L1 fields and still found a penalty. Later versions retain that robustness check and keep journals as the main definition. | Already present; main choice unchanged |
:::
The later documents do contain substantive revisions: an updated retraction sample, explicit COVID sample sizes and effect changes, reorganized methods and supplementary material, improved replication links, and the new multidimensional-quality caveat. The principal estimates and conclusions remain stable. The February manuscript predates both Nature acceptance and the public Unjournal evaluation; the Nature paper was accepted on April 18, 2025, while the public evaluation is dated May 21. There is no posted Unjournal author response. Without private transmission dates, none of these revisions should be attributed to the evaluation. We also lack the separate February supplementary files, so supplementary-material changes can be established only from August 2024 to the Nature version.
### Audit of byte-identical cases (updated July 18, 2026)
An identical current PDF is potentially informative, but only if the local input is credibly the document that was evaluated. Repository history was not enough: all 17 local inputs entered this repository after their evaluations. We therefore checked official version histories, archived pre-evaluation PDFs, distinctive page-level references in the evaluations, and fresh publisher downloads.
Thirteen cases now support the limited statement **“no observed public document change as of July 18, 2026.”** This does not imply that authors ignored the evaluation. They may have revised another manuscript, made changes that are not publicly available, or decided that no revision was warranted.
::: {.provenance-table}
| Paper | Evidence binding the evaluated and current documents |
|---|---|
| *Pharmaceutical Pricing and R&D as a Global Public Good* | The official NBER record retains its May 2023 issue date with no revision date; a fresh publisher download has the same hash. |
| *Towards Best Practices in AGI Safety and Governance* | arXiv lists only version 1 (May 11, 2023); the current PDF is byte-identical. |
| *Choose Your Moments: NIH Peer Review and Scientific Risk Taking* | The official NBER record retains its June 2023 issue date with no revision date; a fresh publisher download has the same hash. |
| *The Returns to Science in the Presence of Technological Risks* | The evaluation identifies arXiv version 2 (May 9, 2024); arXiv lists no later version. |
| *Effects of Emigration on Rural Labor Markets* | The evaluation quotes distinctive page-level text in the October 2017 NBER PDF; the current file has the same hash. |
| *Legalizing Entrepreneurship* | The evaluation cites distinctive page-specific text, including an unusual typo, in the March 2023 revision; the current file has the same hash. |
| *The Benefits and Costs of Guest Worker Programs* | A pre-evaluation Wayback capture and the current NBER PDF are byte-identical. |
| *The Comparative Impact of Cash Transfers and a Psychotherapy Program* | A pre-evaluation Wayback capture and the current NBER PDF are byte-identical. |
| *Maternal Cash Transfers for Child Development* | A distinctive page-level quotation binds the evaluation to the August 2025 NBER revision; the current publisher PDF has the same hash. |
| *Stagnation and Scientific Incentives* | A pre-evaluation Wayback capture and the current NBER PDF are byte-identical. |
| *Intergenerational Child Mortality Impacts of Deworming* | Distinctive page and table references bind the evaluation to the original April 2023 NBER PDF; NBER lists no later revision and the current file has the same hash. |
| *Economic versus Epidemiological Approaches to Policy Evaluation* | A distinctive figure-level comparison binds the evaluation to the July 2022 NBER PDF; NBER lists no later revision and the current file has the same hash. |
| *The Long-Run Effects of Psychotherapy on Depression, Beliefs, and Economic Outcomes* | A pre-evaluation Wayback capture and a version-specific appendix reference bind the evaluation to the May 2022 NBER PDF; the current NBER file is byte-identical. An author-hosted January 2023 draft was ruled out because its corresponding appendix table contains a different analysis. |
:::
The other four initially identical pairs should not be counted as no-change findings. Two have now been repaired by selecting the author-shared or corrected endpoint and appear in the comparison table above. One paper is known to have been revised, but the revised manuscript is not publicly available; one record had no completed evaluation. These failures show why a hash comparison without source-history checks can give the wrong answer.
::: {.callout-note collapse="true"}
## Pipeline and caveats
**Current scripts**: `scripts/paper_response_evidence.py` for source snapshots, validation, and comparison cards; `scripts/screen_paper_response_matches.py` for deterministic, placebo-benchmarked suggestion-to-change leads; `scripts/run_paper_response_agents.py` for optional bounded, review-only model triage.
- **Historical screen shown below**: before version = PDF sent to evaluators; after version = then-current NBER/arXiv PDF, fetched April 2026. Eight pairs had meaningful text changes and a matched evaluation file.
- **Current validation**: the refresh keeps immutable PDF snapshots; verifies paper identity and chronology; produces page- and section-anchored change cards; and puts ambiguous cases into human review. A transient endpoint failure now preserves the last captured comparison with an explicit cached-snapshot warning instead of erasing it from the queue.
- **Automated correspondence check**: suggestion cues must have valid source anchors. Matches are discounted when the same concepts occur in a local window anywhere in the earlier paper and are benchmarked against matches to other papers' changes. The output is a priority queue, not a response label.
- **Models**: the historical Opus screen used bounded extracted text, so it could not reliably assess figures, tables, or all document context. The current agent triage is also deliberately non-decisive: it can identify evidence to inspect, but cannot label causal influence.
- **Interpretation**: a newer version does not imply that changes were evaluation-driven. Some papers are already being revised, and a substantial revision can have unrelated causes.
:::
```{r}
#| label: llm-attribution-load
#| code-summary: "Load and merge LLM + manual data"
nn <- function(x, default = NA) if (!is.null(x)) x else default
llm_results_path <- "data/paper_change_llm_results.json"
# Signal tier labels used throughout — define once
tier_levels <- c(
"Confirmed, LLM >=40%",
"Confirmed, LLM <40%",
"LLM >=30% (not confirmed)",
"LLM 10-29%",
"LLM <10%"
)
tier_colors_llm <- c(
"Confirmed, LLM >=40%" = "#1a7a47",
"Confirmed, LLM <40%" = "#2D9D5E",
"LLM >=30% (not confirmed)" = "#5AE08A",
"LLM 10-29%" = "#a8d5b5",
"LLM <10%" = "#d0e8d8"
)
if (file.exists(llm_results_path)) {
llm_raw <- fromJSON(llm_results_path, simplifyVector = FALSE)
llm_df <- lapply(llm_raw, function(r) {
oa <- r$overall_assessment
data.frame(
paper_title = nn(r$paper_title, ""),
adj_status_csv = nn(r$adj_status, ""),
deposit_after_uj = isTRUE(r$deposit_after_uj),
text_chg_pct = nn(r$text_length_change_pct, NA_real_),
additions = nn(r$additions_count, NA_integer_),
deletions = nn(r$deletions_count, NA_integer_),
n_major_changes = length(nn(r$major_changes, list())),
n_suggestions = length(nn(r$evaluator_suggestions, list())),
pct_influenced = if (!is.null(oa)) nn(oa$pct_likely_influenced, NA_real_) else NA_real_,
attr_confidence = if (!is.null(oa)) nn(oa$confidence, NA_real_) else NA_real_,
narrative = if (!is.null(oa)) nn(oa$narrative, "") else "",
eval_found = !is.null(r$eval_file) && nchar(nn(r$eval_file, "")) > 0,
skipped = !is.null(r$skipped_reason),
stringsAsFactors = FALSE
)
}) |> bind_rows()
llm_analyzed <- llm_df |>
filter(!skipped & eval_found & n_major_changes > 0 & !is.na(pct_influenced))
llm_enriched <- llm_analyzed |>
left_join(df |> select(paper_title, research_area, pubpub_link), by = "paper_title") |>
mutate(
manual_tier = case_when(
adj_status_csv == "evidence of updating" ~ "Confirmed update",
adj_status_csv == "Stated intention to update" ~ "Stated intention",
adj_status_csv == "mixed evidence/minor updating" ~ "Mixed / minor",
adj_status_csv == "Unlikely to update" ~ "Unlikely",
TRUE ~ "Unclassified"
),
combined_tier = case_when(
manual_tier == "Confirmed update" & pct_influenced >= 40 ~ tier_levels[1],
manual_tier == "Confirmed update" ~ tier_levels[2],
pct_influenced >= 30 ~ tier_levels[3],
pct_influenced >= 10 ~ tier_levels[4],
TRUE ~ tier_levels[5]
),
combined_tier = factor(combined_tier, levels = tier_levels)
)
n_analyzed <- nrow(llm_enriched)
n_total_fetched <- nrow(llm_df)
med_pct <- median(llm_enriched$pct_influenced, na.rm = TRUE)
n_high <- sum(llm_enriched$pct_influenced >= 30, na.rm = TRUE)
} else {
llm_df <- llm_analyzed <- llm_enriched <- data.frame()
n_analyzed <- n_total_fetched <- n_high <- 0
med_pct <- NA_real_
}
```
```{r}
#| label: llm-attribution-summary
#| results: asis
#| code-summary: "Summary"
if (nrow(llm_enriched) > 0) {
n_confirmed <- sum(llm_enriched$manual_tier == "Confirmed update")
n_llm_high <- sum(llm_enriched$manual_tier == "Unclassified" &
llm_enriched$pct_influenced >= 30)
cat(glue::glue(
"Of {n_total_fetched} papers with fetchable DOIs, {n_analyzed} had meaningful text ",
"changes and a matched evaluation. {n_confirmed} are manually confirmed updates; ",
"of the remaining {n_analyzed - n_confirmed}, the LLM finds {n_llm_high} with at least 30% ",
"of changes likely driven by evaluator feedback (median across all: {round(med_pct)}%)."
))
}
```
```{r}
#| label: fig-combined-waffle
#| fig-cap: "April tracking snapshot for all 57 papers (each square = 1 paper); adjustment status had been assessed for 22. Green tones: papers where LLM analysis was run, shaded by attribution score and recorded confirmation status. Blue: recorded updates without LLM analysis. Orange/grey: stated intention, weak signal, or not yet assessed."
#| fig-height: 4.5
if (nrow(llm_enriched) > 0) {
# Build one row per paper with tier assignment
waffle_llm <- llm_enriched |>
select(paper_title, combined_tier) |>
mutate(group = as.character(combined_tier))
waffle_manual <- df |>
filter(!paper_title %in% llm_enriched$paper_title) |>
mutate(group = case_when(
adj_status_clean == "Evidence of updating" ~ "Confirmed (manual only)",
adj_status_clean == "Stated intention to update" ~ "Stated intention",
adj_status_clean == "Mixed / minor updating" ~ "Mixed / minor",
adj_status_clean == "Unlikely to update" ~ "Unlikely",
TRUE ~ "Not yet assessed"
)) |>
select(paper_title, group)
waffle_all_groups <- c(tier_levels,
"Confirmed (manual only)", "Stated intention",
"Mixed / minor", "Unlikely", "Not yet assessed")
waffle_colors <- c(
tier_colors_llm,
"Confirmed (manual only)" = "#2B7CE9",
"Stated intention" = "#7EB8F7",
"Mixed / minor" = "#E8722A",
"Unlikely" = "#C45A1E",
"Not yet assessed" = "#CBD5E1"
)
waffle_data <- bind_rows(waffle_llm, waffle_manual) |>
mutate(group = factor(group, levels = waffle_all_groups)) |>
arrange(group) |>
mutate(rank = row_number(),
x = (rank - 1) %% 9,
y = -((rank - 1) %/% 9))
ggplot(waffle_data, aes(x = x, y = y, fill = group)) +
geom_tile(color = "white", linewidth = 1.5) +
coord_equal() +
scale_fill_manual(values = waffle_colors, name = NULL,
drop = FALSE) +
theme_void() +
theme(legend.position = "right",
legend.text = element_text(size = 9),
plot.title = element_text(size = 11, face = "plain",
margin = margin(b = 6)),
plot.caption = element_text(size = 8, color = "grey40",
hjust = 0, margin = margin(t = 8))) +
labs(title = "All 57 tracked papers — each square = 1 paper",
caption = "LLM % = share of major post-evaluation changes attributed to evaluator feedback (Claude Opus 4.6)")
}
```
```{r}
#| label: fig-combined-dot
#| fig-cap: "LLM attribution for the 8 papers with pre/post versions compared. x-axis: estimated % of major changes attributed to evaluator feedback (Claude Opus 4.6, conservative). Point size scales with text change magnitude. Green = manually confirmed update; blue = not yet manually classified. Dashed line at 30%."
#| fig-height: 3.8
if (nrow(llm_enriched) > 0) {
dot_colors <- c("Confirmed update" = "#2D9D5E", "Unclassified" = "#2B7CE9")
llm_enriched |>
mutate(paper_short = str_trunc(paper_title, 46)) |>
ggplot(aes(x = pct_influenced, y = reorder(paper_short, pct_influenced),
color = manual_tier, size = text_chg_pct)) +
geom_vline(xintercept = 30, linetype = "dashed", color = "grey55", linewidth = 0.5) +
geom_point(alpha = 0.85) +
scale_color_manual(values = dot_colors, name = "April tracking category") +
scale_size_continuous(range = c(3, 9), name = "Text change %") +
scale_x_continuous(limits = c(0, 72), labels = \(x) paste0(x, "%"),
breaks = c(0, 15, 30, 50, 70)) +
labs(x = "% of major changes attributed to evaluator feedback", y = NULL) +
theme_uj() +
theme(legend.position = "bottom", legend.box = "vertical",
legend.margin = margin(0, 0, 0, 0))
}
```
```{r}
#| label: tbl-llm-attribution
#| tbl-cap: "Papers with LLM attribution results, sorted by % of changes attributed to evaluator feedback. 'Confirmed' = manually verified by Unjournal staff. Signal tier: 'Confirmed, LLM >=40%' = manually confirmed AND LLM finds strong corroboration; 'Confirmed, LLM <40%' = confirmed but weaker LLM signal; 'LLM >=30% (not confirmed)' = unconfirmed but LLM finds likely influence."
#| code-summary: "Combined evidence table"
#| eval: !expr knitr::is_html_output()
if (nrow(llm_enriched) > 0) {
tier_bg <- c(
"Confirmed, LLM \u226540%" = "#c8e6c9",
"Confirmed, LLM <40%" = "#d4edda",
"LLM \u226530% (not confirmed)" = "#e8f5e9",
"LLM 10\u201329%" = "#fff3e0",
"LLM <10%" = "#f8fafc"
)
tbl_llm <- llm_enriched |>
arrange(desc(pct_influenced)) |>
mutate(
Title = ifelse(
!is.na(pubpub_link) & nchar(pubpub_link) > 0,
paste0('<a href="', pubpub_link, '" target="_blank">',
str_trunc(paper_title, 60), '</a>'),
str_trunc(paper_title, 60)
),
`Manual` = manual_tier,
`LLM %` = paste0(round(pct_influenced), "%"),
`Conf.` = paste0(attr_confidence, "/5"),
`Signal tier` = combined_tier,
`LLM narrative` = str_trunc(narrative, 350)
) |>
select(Title, Manual, `LLM %`, Conf., `Signal tier`, `LLM narrative`)
datatable(
tbl_llm,
escape = FALSE,
rownames = FALSE,
options = list(
pageLength = 5,
dom = "tip",
scrollX = TRUE,
columnDefs = list(
list(width = "18%", targets = 0),
list(width = "11%", targets = 1),
list(width = "6%", targets = 2),
list(width = "5%", targets = 3),
list(width = "16%", targets = 4),
list(width = "44%", targets = 5)
)
)
) |>
formatStyle("Signal tier",
backgroundColor = styleEqual(names(tier_bg), unname(tier_bg)))
} else {
cat("*No LLM attribution results available yet.*")
}
```
## Summary Statistics
```{r}
#| label: summary-numbers
#| code-summary: "Compute headline statistics"
n_total <- nrow(df)
n_assessed <- df |> filter(adj_status_clean != "Not yet assessed") |> nrow()
n_evidence <- df |> filter(adj_status_clean == "Evidence of updating") |> nrow()
n_intention <- df |> filter(adj_status_clean == "Stated intention to update") |> nrow()
n_any_positive <- df |>
filter(adj_status_clean %in% c("Evidence of updating",
"Stated intention to update",
"Mixed / minor updating")) |> nrow()
n_formal <- df |> filter(author_response_clean == "Formal response") |> nrow()
n_any_resp <- df |>
filter(author_response_clean %in% c("Formal response", "Informal response")) |> nrow()
```
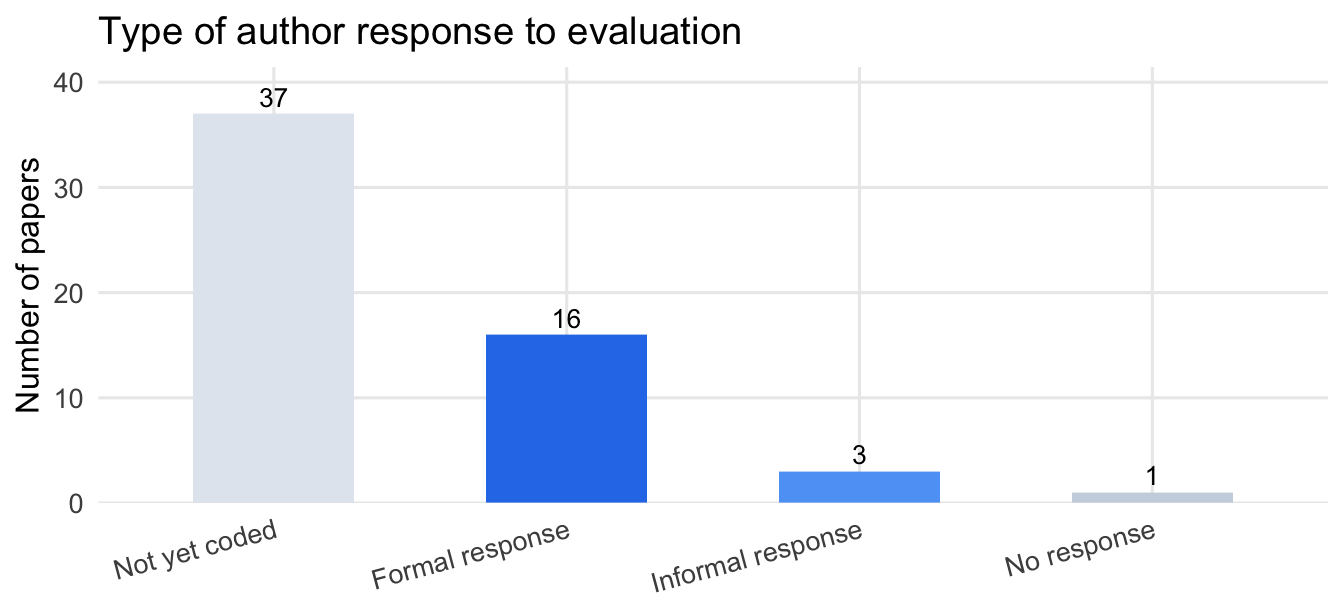
Of `r n_total` tracked evaluations, `r n_assessed` have an assessed adjustment status. Among these: `r n_evidence` are coded as showing clear evidence of substantive updating, `r n_intention` as stating an intention to update, and `r n_any_positive` as showing at least some positive signal. Response status is recorded for only part of the set: `r n_any_resp` papers have a recorded formal or informal response, of which `r n_formal` are formal written responses.
```{r}
#| label: fig-response-bar
#| fig-cap: "Type of author response to Unjournal evaluation. 'Not yet coded' indicates the response status has not been assessed for those papers (37 blanks in data); this is distinct from confirmed non-response (only 1 paper is explicitly coded as no response)."
#| fig-height: 3.2
resp_colors <- c(
"Formal response" = "#2B7CE9",
"Informal response" = "#5DA3F5",
"No response" = "#CBD5E1",
"Not yet coded" = "#E2E8F0"
)
df |>
count(author_response_clean) |>
ggplot(aes(x = reorder(author_response_clean, -n), y = n,
fill = author_response_clean)) +
geom_col(width = 0.55, show.legend = FALSE) +
geom_text(aes(label = n), vjust = -0.4, size = 3.5) +
scale_fill_manual(values = resp_colors) +
scale_y_continuous(expand = expansion(mult = c(0, 0.12))) +
labs(x = NULL, y = "Number of papers",
title = "Type of author response to evaluation") +
theme_uj() +
theme(axis.text.x = element_text(angle = 15, hjust = 1))
```
## Full Tabulation
::: {.callout-note collapse="true"}
## All 57 tracked evaluations
Click column headers to sort; use the search box to filter. Adjustment status is color-coded: green = positive signal, orange = minor/uncertain, grey = unlikely or not yet assessed.
```{r}
#| label: tbl-full
#| code-summary: "Build interactive DT table"
#| eval: !expr knitr::is_html_output()
tbl <- df |>
mutate(
title_linked = if_else(
!is.na(pubpub_link) & pubpub_link != "",
paste0('<a href="', pubpub_link, '" target="_blank">',
str_trunc(paper_title, 72), '</a>'),
str_trunc(paper_title, 72)
),
authors_short = str_trunc(authors, 40),
nb_icon = if_else(
!is.na(nb_link) & nb_link != "",
paste0('<a href="', nb_link, '" target="_blank" title="NotebookLM">📖</a>'),
""
)
) |>
select(Paper = title_linked, Authors = authors_short,
Area = research_area, Response = author_response_clean,
Adjustment = adj_status_clean, `Pub.` = pub_status, NB = nb_icon)
adj_bg <- c(
"Evidence of updating" = "#d4edda",
"Stated intention to update" = "#e8f5e9",
"Mixed / minor updating" = "#fff3e0",
"Unlikely to update" = "#fce4d4",
"Not yet assessed" = "#f8fafc"
)
datatable(tbl, escape = FALSE, rownames = FALSE, filter = "top",
options = list(
pageLength = 8, autoWidth = FALSE, scrollX = TRUE, dom = "lfrtip",
columnDefs = list(
list(width = "36%", targets = 0),
list(width = "18%", targets = 1),
list(width = "8%", targets = 2),
list(width = "11%", targets = 3),
list(width = "16%", targets = 4),
list(width = "8%", targets = 5),
list(width = "3%", targets = 6)
)
),
caption = "All tracked Unjournal evaluations. NB = NotebookLM analysis link."
) |>
formatStyle("Adjustment",
backgroundColor = styleEqual(names(adj_bg), unname(adj_bg)))
```
:::