---
title: "Results: Critiques & Key Issues"
engine: knitr
execute:
freeze: auto
---
::: {.content-visible when-format="pdf"}
Detailed paper-by-paper critique comparisons (matched issue pairs, severity labels, structural differences) are available in the online supplement at <https://llm-uj-research-eval.netlify.app/results_critiques.html>.
:::
::: {.content-visible when-format="html"}
```{r}
#| label: setup-critiques
#| code-summary: "Setup and libraries"
#| code-fold: true
#| message: false
#| warning: false
library("tidyverse")
library("jsonlite")
library("knitr")
library("kableExtra")
library("DT")
library("reticulate")
# Theme colors — crisp palette (matching results.qmd)
UJ_ORANGE <- "#E8722A" # vivid saffron orange
UJ_GREEN <- "#2D9D5E" # rich emerald green
UJ_BLUE <- "#2B7CE9" # clear azure blue
# Severity colors for badges
SEV_NECESSARY <- "#D62839" # Bright crimson
SEV_OPTIONAL <- "#E8722A" # Saffron orange
SEV_UNSURE <- "#8B95A2" # Cool grey
theme_uj <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(
panel.grid.minor = element_blank(),
panel.grid.major = element_line(linewidth = 0.3, color = "grey88"),
plot.title = element_text(face = "bold", size = rel(1.1)),
plot.title.position = "plot",
plot.subtitle = element_text(color = "grey40", size = rel(0.9)),
plot.caption = element_text(color = "grey50", size = rel(0.8), hjust = 0),
axis.title = element_text(size = rel(0.95)),
axis.text = element_text(size = rel(0.88)),
legend.position = "bottom",
legend.text = element_text(size = rel(0.88)),
legend.title = element_text(size = rel(0.9), face = "bold"),
strip.text = element_text(face = "bold", size = rel(0.95))
)
}
# Function to create severity badge HTML
severity_badge <- function(severity) {
sev <- tolower(trimws(severity))
if (grepl("necessary", sev)) {
return('<span style="background-color:#D62839;color:white;padding:2px 6px;border-radius:3px;font-size:0.8em;">Necessary</span>')
} else if (grepl("optional", sev)) {
return('<span style="background-color:#E8722A;color:white;padding:2px 6px;border-radius:3px;font-size:0.8em;">Optional</span>')
} else if (sev != "") {
return('<span style="background-color:#8B95A2;color:white;padding:2px 6px;border-radius:3px;font-size:0.8em;">Unsure</span>')
}
return('<span style="background-color:#bdc3c7;color:white;padding:2px 6px;border-radius:3px;font-size:0.8em;">\u2014</span>')
}
# Function to truncate text for table display
truncate_text <- function(text, max_chars = 80) {
if (nchar(text) > max_chars) {
paste0(substr(text, 1, max_chars), "...")
} else {
text
}
}
```
This chapter reports preliminary results from comparing LLM-identified key issues against human expert critiques. The analysis uses LLM-based assessment (GPT-5.2 Pro as judge) to measure human-issue coverage and the LLM overlap rate; human validation of these alignment scores is underway.
::: callout-warning
This section is under active development. Human-issue coverage and LLM overlap-rate estimates below are LLM-assessed; manual annotation is in progress.
:::
**Data sources.** We compare GPT-5.2 Pro key issues (structured output from the focal evaluation run, January 2026) against human expert critiques curated from The Unjournal's internal tracking database, where evaluation managers synthesize evaluator feedback using severity labels ("Necessary", "Optional but important", "Unsure"). The focal run covered 14 papers; one pair (Peterman et al. 2025) is excluded from the analysis because the curated human critique was misattributed---it belongs to The Unjournal's evaluation of a different manuscript ("Maternal cash transfers for gender equity and child development"), which is not part of this study's sample. The GPT-5.2 Pro judge itself flagged the mismatch, and we verified it against the paper PDF; the excluded pair is documented in `results/key_issues_comparison.md`.
```{r}
#| label: load-comparison-data
#| code-fold: true
#| code-summary: "Load comparison data"
# Load the matched comparison data
comparison_file <- "results/key_issues_comparison.json"
comparison_results_file <- c(
"results/key_issue_comp_results.json",
"results/key_issues_comparison_results.json"
)
comparison_results_file <- comparison_results_file[file.exists(comparison_results_file)][1]
if (file.exists(comparison_file)) {
comparison_data <- fromJSON(comparison_file)
n_papers <- nrow(comparison_data)
} else {
comparison_data <- NULL
n_papers <- 0
}
# Load LLM-based comparison results if available. The legacy precision_pct
# field is displayed as the LLM overlap rate.
if (!is.null(comparison_data) && !is.na(comparison_results_file)) {
llm_results_raw <- fromJSON(comparison_results_file)
llm_results <- llm_results_raw |>
as_tibble() |>
unnest_wider(comparison) |>
select(
gpt_paper,
coverage_pct,
precision_pct,
# New format uses matched_pairs, unmatched_human, unmatched_llm
any_of(c("matched_pairs", "unmatched_human", "unmatched_llm")),
# Old format used missed_issues, extra_issues (keep for backward compat)
any_of(c("missed_issues", "extra_issues")),
overall_rating,
overall_justification,
detailed_notes
)
comparison_data <- comparison_data |>
left_join(llm_results, by = "gpt_paper")
}
# Update paper count after loading
if (!is.null(comparison_data)) {
n_papers <- nrow(comparison_data)
}
```
We matched **`r n_papers` papers** with both GPT-5.2 Pro key issues and human expert critiques.
**LLM-based assessment.** The comparison was assessed using GPT-5.2 Pro, which evaluated coverage (what proportion of human concerns GPT identified) and the LLM overlap rate (what proportion of LLM issues matched a curated human concern).
- **Coverage**: Proportion of *consensus* human issues that have any LLM match (match quality >= 30%)
- **Weighted Coverage**: Mean match quality across all human issues (treating unmatched issues as 0%)
- **LLM overlap rate**: Proportion of LLM issues that match a curated human concern
::: callout-note
## Caveat on the LLM overlap rate
The LLM overlap rate only reflects whether LLM issues match the *consensus* human issues curated in Coda---those prioritized by evaluation managers as the most important concerns. Many LLM-identified issues may have been noted by one or more individual human evaluators but were not included in this curated set. A low overlap rate does not mean the LLM raised irrelevant or incorrect concerns; it may simply reflect issues that were not prioritized in the consensus summary.
:::
```{r}
#| label: check-llm-results
#| code-fold: true
# Check if LLM comparison results are available
has_llm_results <- !is.null(comparison_data) &&
n_papers > 0 &&
"coverage_pct" %in% names(comparison_data) &&
any(!is.na(comparison_data$coverage_pct))
```
```{r}
#| label: llm-assessment-summary
#| tbl-cap: "LLM assessment of GPT vs human critique alignment"
if (has_llm_results) {
# Filter to papers with valid LLM results
llm_results <- comparison_data |>
filter(!is.na(coverage_pct) & !is.na(precision_pct))
summary_stats <- llm_results |>
summarise(
`Papers Assessed` = n(),
`Mean Coverage (%)` = round(mean(coverage_pct, na.rm = TRUE), 1),
`Mean LLM overlap rate (%)` = round(mean(precision_pct, na.rm = TRUE), 1),
`Coverage Range` = paste0(min(coverage_pct, na.rm = TRUE), "-", max(coverage_pct, na.rm = TRUE)),
`LLM overlap-rate range` = paste0(min(precision_pct, na.rm = TRUE), "-", max(precision_pct, na.rm = TRUE))
) |>
mutate(across(everything(), as.character)) |>
pivot_longer(everything(), names_to = "Metric", values_to = "Value")
kable(summary_stats, align = c("l", "r"))
}
```
```{r}
#| label: fig-coverage-precision
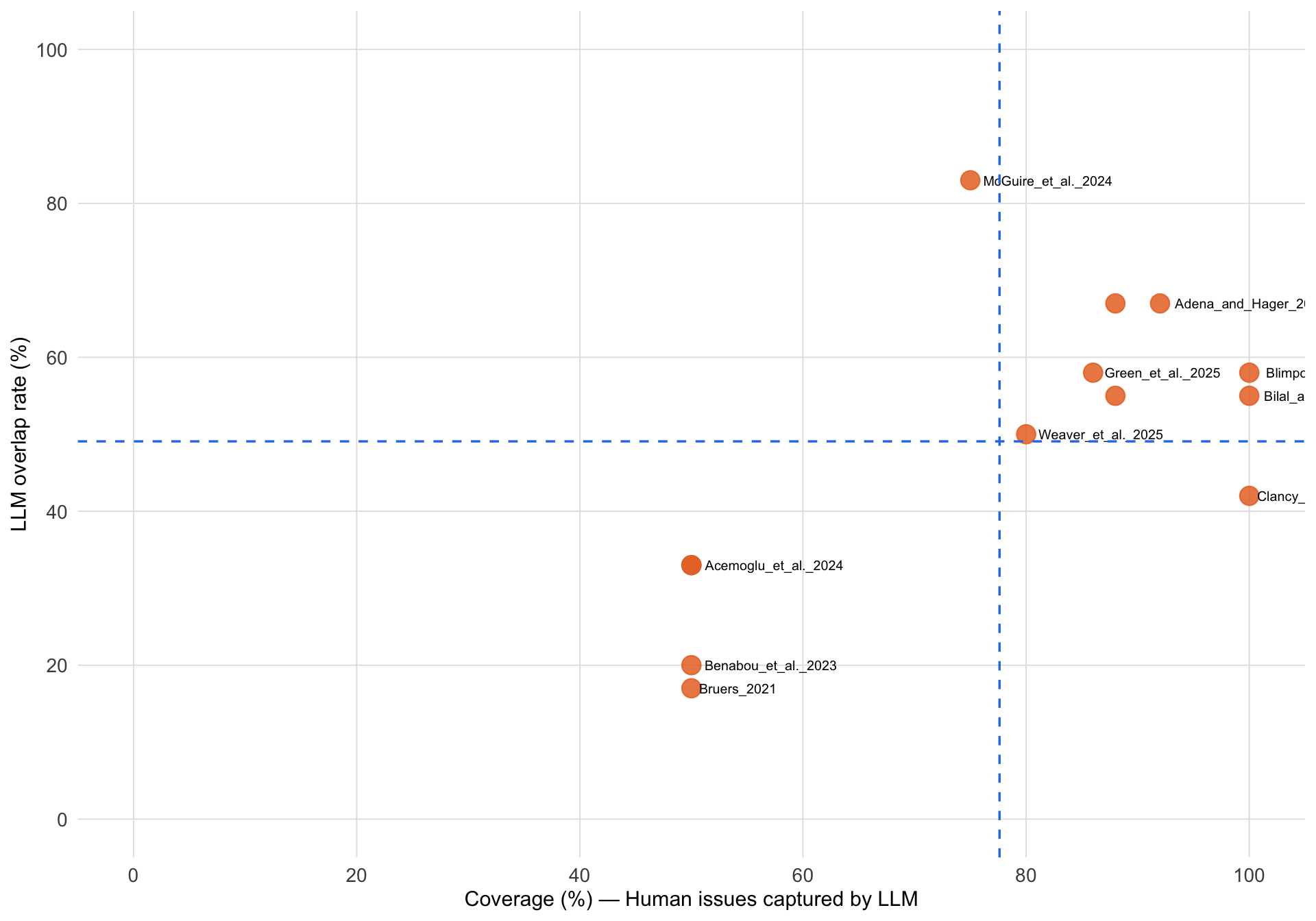
#| fig-cap: "Coverage (% of human-identified issues captured by the LLM) vs LLM overlap rate (% of LLM-raised issues matching a curated human concern), as assessed by GPT-5.2 Pro acting as judge. Each point is one paper. Dashed blue lines mark cross-paper means. Papers in the upper-right show strong human\u2013LLM critique alignment."
#| fig-width: 10
#| fig-height: 7
if (has_llm_results) {
llm_results <- comparison_data |>
filter(!is.na(coverage_pct) & !is.na(precision_pct)) |>
mutate(paper_short = str_trunc(gpt_paper, 25))
ggplot(llm_results, aes(x = coverage_pct, y = precision_pct)) +
geom_point(size = 4.5, color = UJ_ORANGE, alpha = 0.85) +
geom_text(aes(label = paper_short), hjust = -0.1, vjust = 0.5, size = 2.6, check_overlap = TRUE) +
geom_vline(xintercept = mean(llm_results$coverage_pct), linetype = "dashed", color = UJ_BLUE, linewidth = 0.6) +
geom_hline(yintercept = mean(llm_results$precision_pct), linetype = "dashed", color = UJ_BLUE, linewidth = 0.6) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20)) +
scale_y_continuous(limits = c(0, 100), breaks = seq(0, 100, 20)) +
labs(
x = "Coverage (%) \u2014 Human issues captured by LLM",
y = "LLM overlap rate (%)"
) +
theme_uj()
}
```
::: {.callout-note collapse="true"}
## Interpretation Guide
- **Coverage**: Percentage of human-identified issues that GPT also captured (in some form). Higher = GPT missed fewer human concerns.
- **LLM overlap rate**: Percentage of GPT issues that match the curated human concern set. Higher means more overlap, but unmatched concerns are not necessarily incorrect.
- **Overall Rating**: Qualitative assessment (Excellent/Good/Moderate/Poor) based on both coverage and overlap metrics.
:::
The coverage-overlap figure above shows substantial variation across papers: some papers achieve high coverage and overlap, while others show the LLM missing key human concerns or raising issues not in the expert consensus. Paper-by-paper comparisons with matched issue pairs, structural difference tables, and the manual annotation tool are available in the [full online version](https://llm-uj-research-eval.netlify.app/results_critiques.html).
:::